- Published on
채팅방 백업
- Authors
- Name
- 박상민
먼저 저희 커피밋에서는 채팅 참여자 한 명이 채팅방을 나가면 채팅방은 폭파가 되고 채팅방과 채팅 메세지를 history 테이블로 백업 시킵니다.
꽤 많은 채팅 메세지 쌓일 것으로 예상해서 응답 시간 측정이 필요하다고 느꼈고 측정 이후 성능 개선 및 트러블슈팅을 한 경험에 대한 포스팅입니다.
아래는 간략하게 표현한 ERD 입니다.
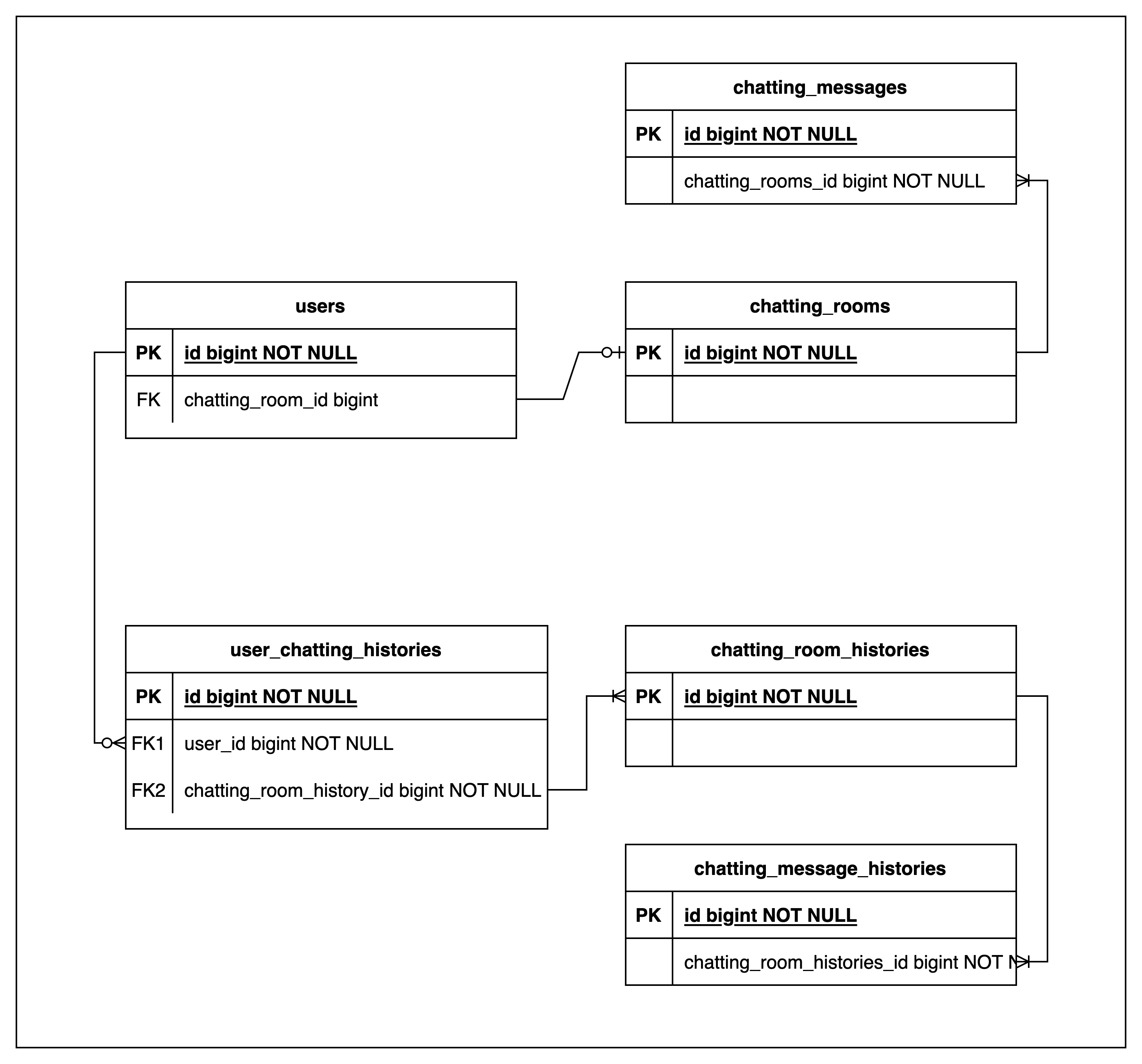
chatting_rooms은 chatting_room_histories, user_chatting_room_histories 로 백업됩니다.
chatting_messages은 chatting_message_histories로 백업됩니다.
아래는 개선 전 백업 Service 코드입니다.

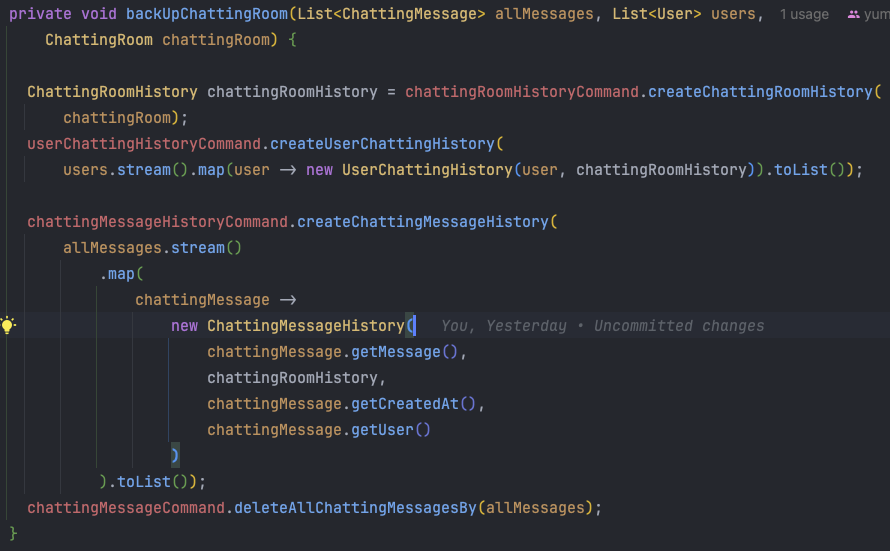
- 채팅방에 할당된 모든 채팅메세지를 가져옵니다.
- backUpChattingRoom()
- ChattingRoomHistory를 생성합니다. (id 값은 ChattingRoom id와 동일합니다.)
- UserChattingRoomHistory를 생성합니다.
- ChattingMessage를 ChattingMessageHistory로 변환하여 저장합니다.
- 채팅방을 삭제합니다.
해당 코드는 JPA로 작성되었고 DB는 MySQL, 아이디 생성 전략은 IDENTITY입니다.
MySQL의 Procedure로 유저, 채팅방, 채팅메세지(10,000건)의 더미데이터를 생성하여 테스트했습니다.
첫 번째 문제 (StackOverflow)

채팅방 퇴장 API를 호출한 결과 StackOverflow가 발생했습니다.
너무 많은 데이터를 가져와서 OutOfMemoryError가 발생하면 이해하겠는데, StackOverflow가 발생해서 의아 했습니다.
디버깅 해본 결과 deleteAllInBatch에서 해당 에러가 발생한 걸 확인했습니다.
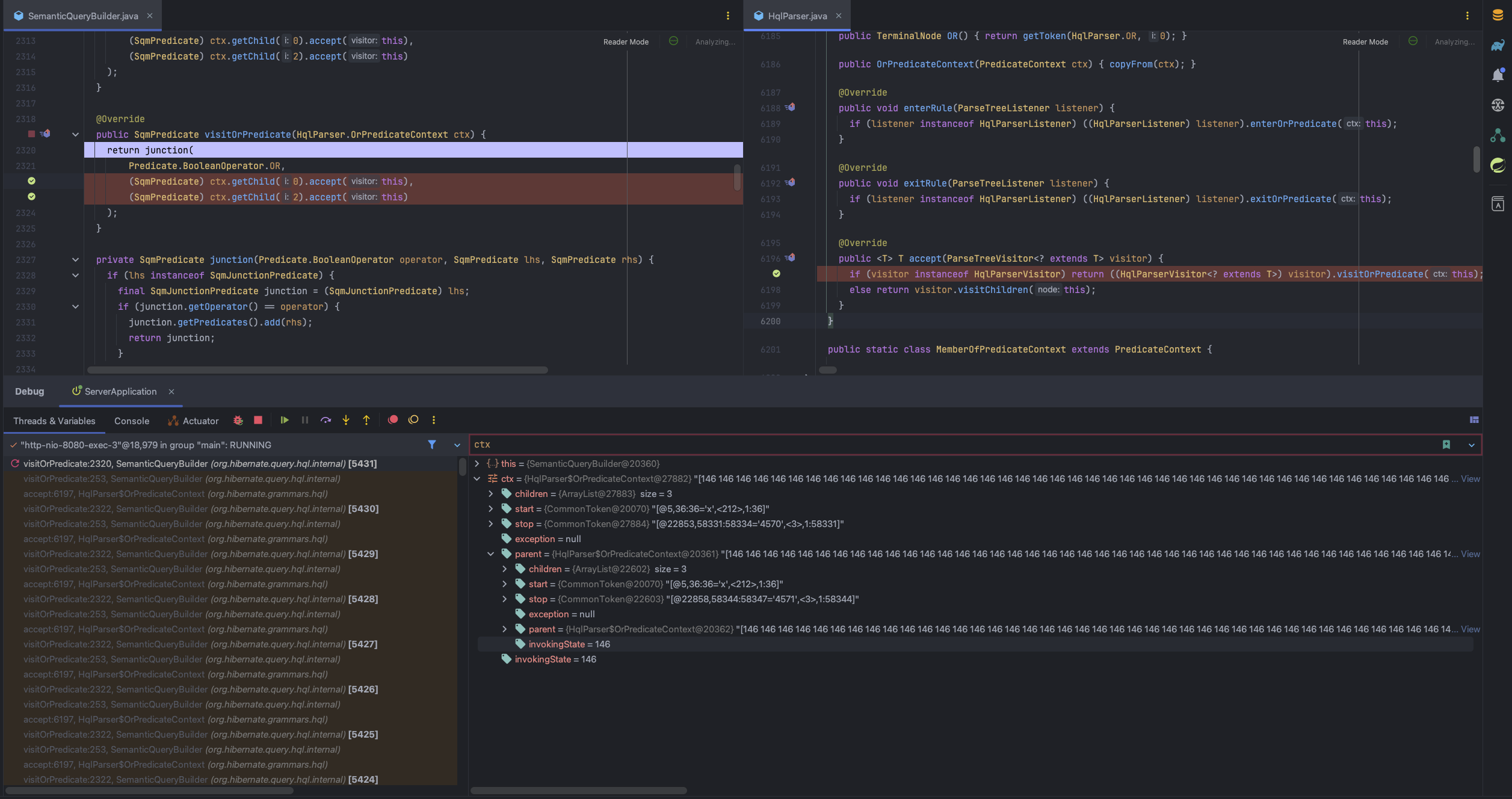
이미지 왼쪽 Threads & Variables를 보시면 accept와 visitOrPredicate가 계속 반복해서 stack에 쌓이는 것이 확인됩니다.
내용을 확인 해보니 HQL을 SQL로 파싱하는 과정에서 해당 메서드들을 호출하는데 10,000만 건의 where 절의 id 들을 모두 파싱하다 보니 StackOverflow가 난 걸로 파악했습니다.
ex) DELETE FROM Person WHERE id = ? OR id = ? OR id = ? OR id = ? OR id = ? id = 1 바인딩하고 id = 2 바인딩하고 …
해당 문제를 일정 단위만큼 삭제하는 것으로 해결했습니다. 추가로 빠른 조회를 위해 Cursor기반의 페이지네이션으로 구현했습니다.
덩달아 findAll 을 할 때 채팅메세지가 너무 많고 여러 요청이 한 번에 들어왔을 때, 혹시 모를 OutOfMemory를 대비해서 고정된 size의 메세지를 가져오도록 변경했습니다.
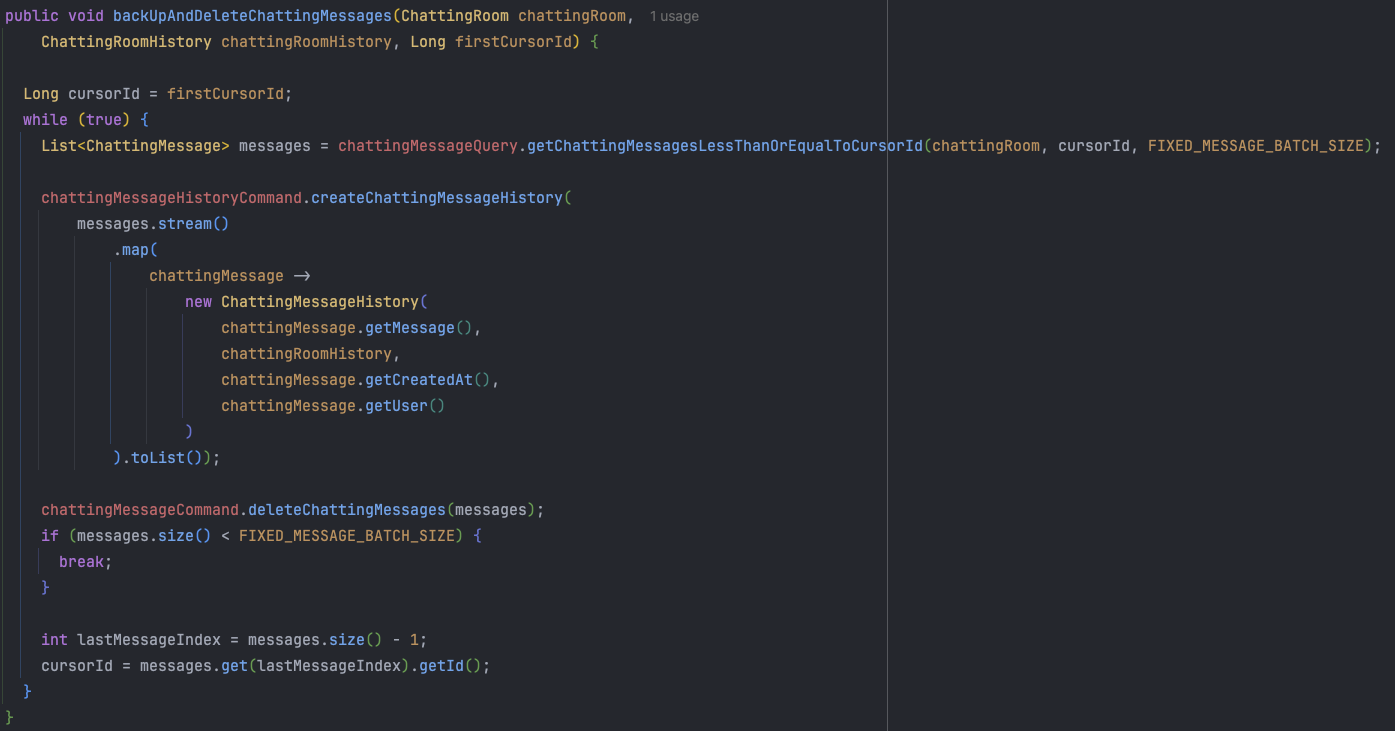
- 고정된 배치 사이즈만큼 ChattingMessage를 가져온다.
- ChattingMessageHistory를 생성한다.
- ChattingMessage를 삭제한다.
- 가져온 ChattingMessage의 사이즈가 고정된 배치 사이즈보다 작다면 모두 삭제된 것으로 while 탈출
두 번째 문제 (너무 긴 응답 시간)
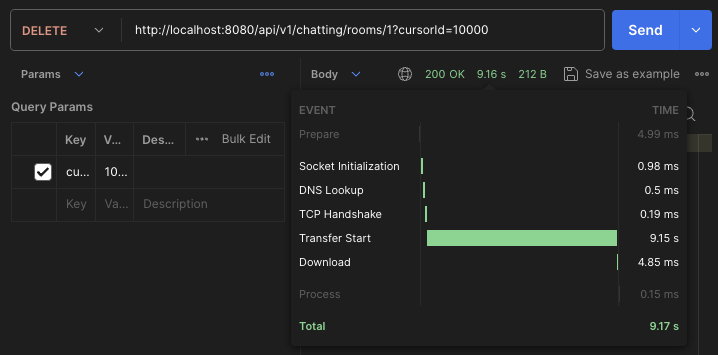
API 응답 시간이 약 9초로 길게 소요됩니다.
백업 과정에서 많은 데이터 생성과 삭제가 일어나기 때문에 조금 긴 응답 시간이 불가피해 보여 비동기로 처리하는 쪽이 좋을 거라고 생각이 되는데, 그래도 최대한 절대적인 시간을 줄이는 것 또한 필요해 보입니다.
각 작업의 지연 시간을 확인한 결과, saveAll 작업이 가장 긴 지연 시간을 보였습니다.
해당 작업은 단 건 Insert로 수행되어 지연 시간이 길게 나타났습니다. 성능을 개선하기 위해 해당 작업을 Batch insert로 변경하려고 합니다.
Batch insert란?
INSERT INTO chatting_message_histories (id, message, chatting_room_history_id, user_id) VALUES (1, '메세지1', 1, 1);
INSERT INTO chatting_message_histories (id, message, chatting_room_history_id, user_id) VALUES (2, '메세지2', 1, 2);
INSERT INTO chatting_message_histories (id, message, chatting_room_history_id, user_id) VALUES (3, '메세지3', 1, 3);
INSERT INTO chatting_message_histories (id, message, chatting_room_history_id, user_id) VALUES (4, '메세지4', 1, 4);
INSERT INTO chatting_message_histories (id, message, chatting_room_id, user_id)
VALUES
(1, '메세지1', 1, 1)
(2, '메세지2', 1, 2)
(3, '메세지3', 1, 3)
(4, '메세지4', 1, 4);
위는 단 건 insert, 아래는 Batch insert 입니다.
INSERT를 실행하는데 소요되는 시간을 N이라고 하고 실제 데이터가 들어갈 때 소요되는 시간을 M이라고 하겠습니다.
10,000 건의 데이터를 1,000 건 씩 분할하여 삽입할 때 아래와 같은 차이가 납니다.
단 건 insert: (10,000 * N + 10,000 * M)
Batch insert: (10,000 * N + 10 * M)
하지만 JPA로 ID 생성 전략이 IDENTITY인 테이블에 Batch Insert가 불가능합니다.
왜 불가능 하냐?
영속성 컨텍스트에서 ID값과 객체가 매핑이 되어 있습니다.
IDENTITY 전략을 사용하면 ID값을 알아야 하기 때문에 객체가 persist 상태가 되더라도 쓰기 지연 저장소에 올라가는 것이 아니라 바로 INSERT 쿼리가 나가게 됩니다. 이렇게 Hibernate에서는 기본적으로 ID값을 꼭 알아야 하게끔 구현이 되어 있습니다.
하지만, Batch insert 경우 모든 Entity의 ID를 알 수가 없습니다. 알아 내고 싶다면 알 수 있는 방법도 당연히 있겠지만 비효율적이라고 생각됩니다. 따라서 Hibernate에서는 Batch insert를 지원하지 않고 단 건 insert만 지원합니다.
JPA에서 IDENTITY 전략이 Batch insert가 안되는 문제를 JDBC의 batchUpdate로 해결했습니다.
JDBC batchUpdate 적용
일단 application.yml에 datasource에 rewriteBatchedStatements=true를 추가해주어야 합니다.
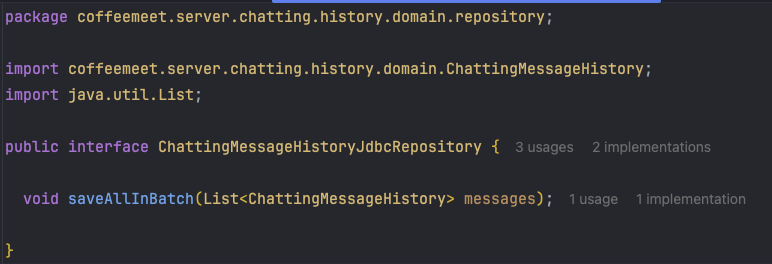
ChattingMessageHistoryJdbcRepository 인터페이스 정의
ChattingMessageHistoryRepositoryImpl 구현체 정의
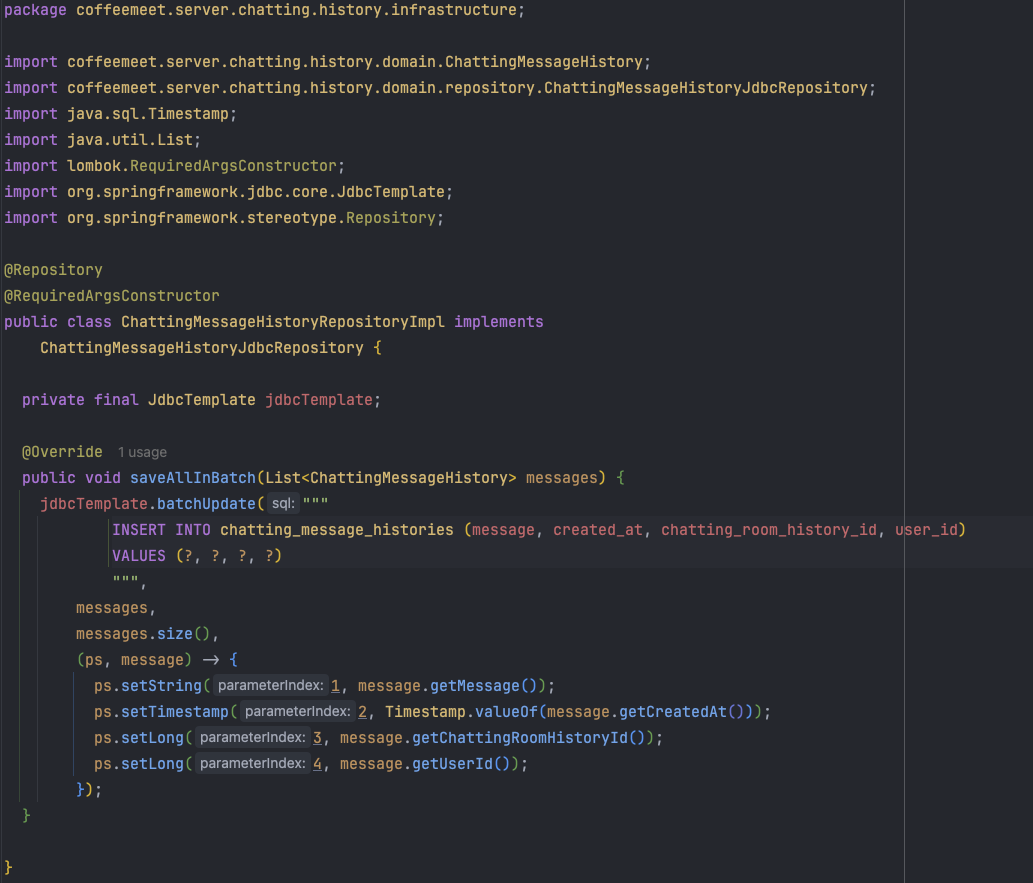 위 코드 실행 중 외래키 제약조건으로 인한 문제가 발생했습니다.
위 코드 실행 중 외래키 제약조건으로 인한 문제가 발생했습니다.

저희의 구조는 ChattingMessageHistory 가 ChattingRoomHistory의 아이디를 외래키 제약조건으로 가지고 있습니다.

먼저 backUpChattingRoom에서 ChattingRoomHistory을 저장합니다.
이후 backUpAndDeleteChattingMessages에서 ChattingMessageHistory가 생성되고 ChattingMessage 삭제됩니다.
ChattingRoomHistory 생성 로직을 보겠습니다.

JPA로 save 됐을 때 해당 쿼리는 DB에 적용이 될까요?
적용이 되지 않습니다. 이유는 JPA는 영속성 컨텍스트의 영향을 받기 때문에 기본적으로 쓰기 지연이 발생합니다.
따라서 해당 쿼리는 쓰기 지연 저장소에 저장되고 Transaction commit 시에 DB에 적용됩니다.
반면 JDBC는 영속성 컨텍스트를 거치지 않고 DB에 바로 접근하게 되고 ChattingRoomHistory insert 쿼리가 선행되지 않았기 때문에 외래키 제약조건에 예외가 발생하게 됩니다.
위의 코드에서 save 를 saveAndFlush로 변경하게 되면 쓰기 지연 저장소를 비우고 DB에 바로 적용되어 예외 없이 정상 작동합니다.

최종 지연 시간
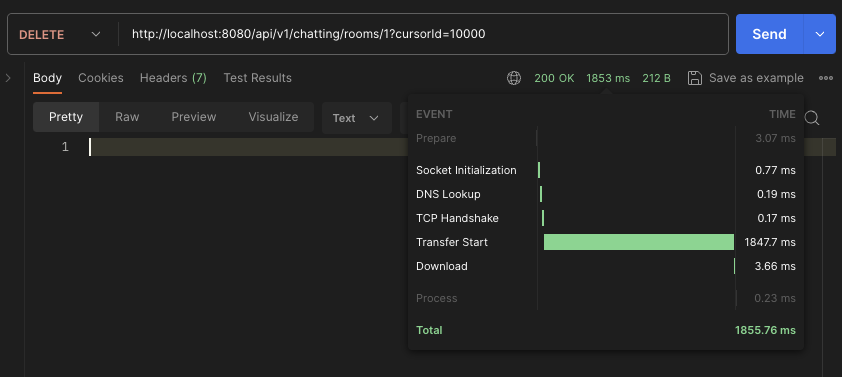
JDBC batchUpdate 적용하여 9.16s -> 1.85s로 단축했습니다.
아래는 각각 5회씩 테스트 한 결과입니다.
| JPA (EACH) | JDBC (BULK) | |
|---|---|---|
| 1회 | 11210 ms | 1939 ms |
| 2회 | 10020 ms | 1868 ms |
| 3회 | 9780 ms | 1905 ms |
| 4회 | 10210 ms | 1871 ms |
| 5회 | 10050 ms | 1850 ms |
| 평균 | 10272 ms | 1886.6 ms |
아래는 batch size에 관한 테스트를 진행한 결과입니다.
| 임계값 | 조회 시간 (JPA) | 저장 시간 (JDBC) | 삭제 시간 (JPA) | 응답 시간 |
|---|---|---|---|---|
| 5,000개 | 172 ms | 462 ms | 2267 ms | 3360 ms |
| 4,000개 | 202 ms | 427 ms | 1853 ms | 2970 ms |
| 3,000개 | 215 ms | 452 ms | 1726 ms | 2860 ms |
| 2,000개 | 207 ms | 477 ms | 1013 ms | 2180 ms |
| 1,000개 | 255 ms | 458 ms | 662 ms | 1939 ms |
| 500개 | 364 ms | 480 ms | 578 ms | 2070 ms |
| 300개 | 462 ms | 498 ms | 618 ms | 2460 ms |
| 100개 | 1041 ms | 588 ms | 1147 ms | 4380 ms |
10,000개 기준 batch size 1,000개를 기점으로 시간이 늘어나는 것을 확인했고 batch size를 1,000개로 고정했습니다.
추가적인 JDBC batchUpate 사용 시 주의점
JPA의 flush 시점 고려 (위에서 언급)
JDBC는 영속성 컨텍스트를 우회하기 때문에 캐시에 있는 데이터가 유효하지 않을 수 있음
외래키 관련 Cascade delete를 수행하지 못함
외래키 제약조건이 있는 1:N 관계에 있는 테이블을 INSERT할 때 외래키 컬럼 등록 어려움
ex) 기존 데이터를 마이그레이션 하는 과정, delivered_item(N), delivery(1)
- 10,000개의 배달을 jdbc batch insert로 생성
- item의 delivery_id을 등록해야 하는데 delivery_id를 알지 못함